Dominic Rigby
Paper Diary
By Dom Rigby
Note: this is GitHub Pages website. If viewing on GitHub, please go to domrigby.github.io for full experience.
📌 Introduction
Welcome to my Paper Diary! Due to the seemingly never ending supply of interesting reinforcement learning papers which have come out in the last few years, I began to try and read at least one per day. I was however having the issue that after a month of two I could not remember for the life of me where I had read that interesting fact, method or algorithm. I therefore began keeping a diary of the papers/blog posts I was reading. I recently decided to start compressing the key points papers into short, bite-size summaries. I hope you find out something useful!
Notes:
- Layout and formatting are continuously improved when time permits.
- Entries are added on the go (often from my phone or iPad) and later refined on my laptop.
⚙️ Website Workings
This website is a user-friendly entry point and summary of the repository. This hosts the top level themes and parts I thought were interesting. All paper summaries are stored in this repository.
A list of papers read and links to their summaries is in the full diary section.
📈 My Interest Areas
I am fascinated by emergent behaviour, especially when this behaviour is diverse and unexpected. I therefore focus tend to focus on reinforcement learning, auto-curriculums and open-endedness, but also enjoy reading how this is made possible through clever engineer and distribution.
Inspired by figure 2 of OMNI-EPIC and policy diversity method in Foundation Model Self Play, I clustered my papers read using the following method:
-
Embedding: I get o4-mini-high to create a one sentence, short description of each paper using this prompt. This description is then embedded using Sentence-Transformers python library.
-
Dimensionality Reduction: The embedding dimension is then reduced from 384D to 30D using PCA and then to 2D using t-SNE and UMAP (in more plots section)
-
Clustering: The resultant 2D data points are then clustered using K-Means. A list of the titles of each paper are fed into GPT-4o using this prompt (link pending), which asks it to come up with a title for each cluster. This gives me some interesting second opinion into the theme I am exploring.
Hover over any data point to see the name of the paper/blog post. On mobile, go into landscape mode and tap.
🔍 Highlights & Lessons Learned
The following section includes:
- Interesting ideas: any ideas I saw in papers which might be useful if someone is tackling a similar problem.
- Useful methods: adding tools to your mental toolbox.
- Concise fundamentals: I try and explain the fundamentals of a topic in a few short bullet points!
1. Reinforcement Learning (RL)
- Moments of uncertainty are the best moments to learn from
- You learn the most when a decision is uncertain as these correspond to “forks in the road” in which making a decision will likely strongly affect the outcome.
- These moments can be described mathematically as high entropy tokens or decisions.
- Unsurprisingly, training on these tokens yields significant performance gains when training reasoning models (80:20 Rule).
- A bit of intuition behind this: Many tokens in language are determined my other words so provide little information in te RL process when they are chosen.
E.g. “I went to the shop”, “to” and “the” are determined by other words so provide little information.
- You don’t learn anything from always winning… but equally little if you are always losing!
- There exists a ‘zone of proximal development’ in which agents are learning the most about what is right and wrong. This is shown simply in methods such as ProRL and Absolute Zero Reasoner in which they filter out consistently correct or incorrect prompts. This process shares some similarities with auto-curriculum learning, of which a more in depth more discussion can be found in section 2.
- It is possible to make Non‑Verifiable Reward Models (e.g. rewards for creative writing!)
- Writing‑Zero trains an LLM based preference model to grade creative writing pieces and then uses this to train agents to become better at creative writing.
- You can use generative AI to expand experience buffer
- SynthER trains a diffusion model to expand the replay buffer with synthetic experiences for mixed real‑fake training.
- You can learn to reason by simply playing games
- Play to Generalise demonstrates that game‑based move prediction enhances reasoning capabilities. Whilst it was trained on games, it showed improved performance on on a variety of out-of-domain tasks (maths and multi-modal reasoning).
- GPU‑Accelerated Environments provide monumental speeds up
- Frameworks like Kinetix and JaxMARL allow you to run tens of thousands of environments in parallel, as well as minimise CPU-GPU overhead.
- This could allow for some LLM-like RL ‘pre-training’ on vast amounts of data from diverse scenarios before fine-tuning to the ones of interest.
- Kinetix demonstrates reasonable zero-shot capability on 2D control tasks by training on randomly generated (then filtered) scenarios.
- I highly recommend visiting their website an having a play around on their online demo: https://kinetix-env.github.io/
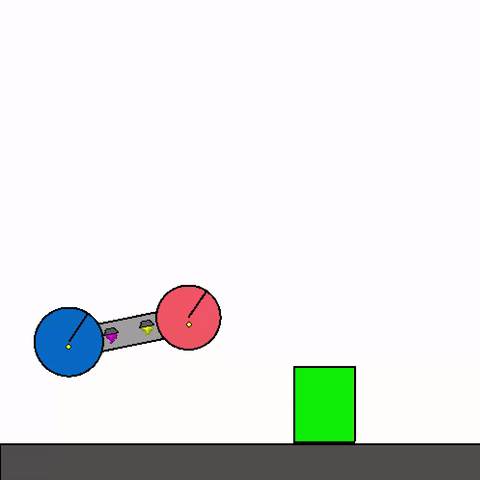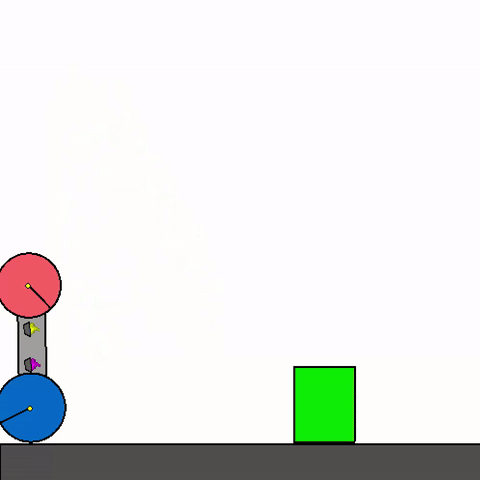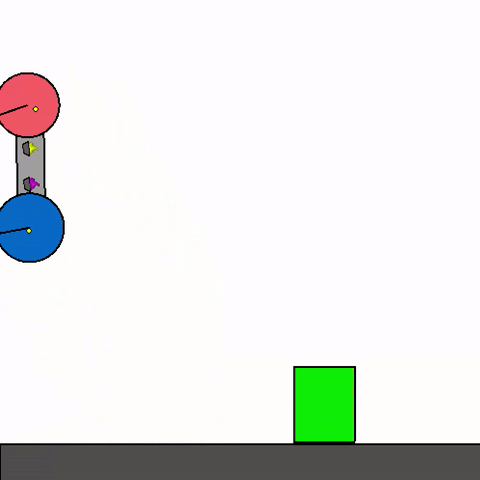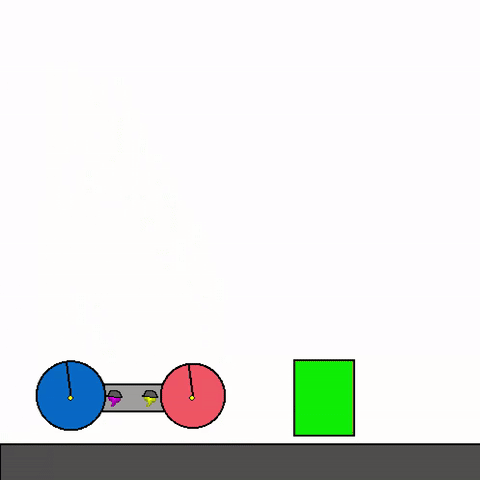
Figure 1: Example of Kinetix general agent zero-shotting unseen handmade scenario [source](https://github.com/FlairOx/Kinetix/)
- Learning to walk in minutes trains locomotive robotic policies in under ten minutes using GPU environments and provides advice on how to tune the PPO hyperparameters to take advantage of the huge parallelism (e.g. massive mini-batches, short rollouts etc).
- Foundation models have a large role to play in future RL:
- Foundation models have intuition about what humans find interesting. They are therefore capable of designing curriculums for RL or being involved in the policy improvement steps.
See more in the open-endedness section of this blog. Summary of a few interesting methods:
- Create environments of interest (OMNI-EPIC, Eurekaverse)
- Writing code based policies and suggesting improvements after view results (Foundation Model Self-Play)
- Reward shaping by CALM
- Foundation models have intuition about what humans find interesting. They are therefore capable of designing curriculums for RL or being involved in the policy improvement steps.
See more in the open-endedness section of this blog. Summary of a few interesting methods:
- Quality Diversity can be used for testing:
- MADRID uses a MAP-Elites style quality diversity search to get diverse set of scenarios the algorithm struggles with. It does this by maximising regret across the search grid.
- The above was done on TiZero (a football playing algorithm) and it found a variety of areas of the pitch in which the agent was not only vulnerable, but did unexpected behaviours like score own-goals.
- Hierarchical planning is the more natural way forward:
- When human plan, we don’t plan how were going to move every muscle in order to get to where we want to go. This would be extremely computationally heavy and make planning over long time horizons impossible, not to mention the drift in our plans due to errors.
- Hierarchical planning breaks down plans into high-level actions, or options, which are then achieved by lower levels in the hierarchy.
E.g. if we wanted to go to the shop, the high level planner might plan to walk down the road and then turn right. The low level planner would then do the actual muscle movement.
- In RL, this tends to be made up of two or more levels or RNN, with the higher levels being called at lower frequencies.
- Forecaster introduces a manager-worker world model framework for this. The manager pick high level goals with which to condition the worker on. It then performs tree search across a set of possible goals in order to pick which one is best.
- Hierarchical Reasoning Model uses this approach but for reasoning.
- Sometimes you need to stop and have a think about it (scaling test time compute)
- Hierarchical Reasoning Model uses a DQN to decide whether the model should continue reasoning (or could be planning if using MCTS or other model based method) or finish. This allows the network to switch between system 1 and system 2 thinking (thinking longer about harder tasks).
2. Open‑Endedness & Auto‑Curricula
Open-endedness and auto-curriculums are crucial for building truly intelligent agents. In the same way that humans didn’t go to the moon by starting working on a rocket, agents can’t achieve superintelligence by just training on a set of pre-defined tasks. Human technology and intelligence has advanced by constantly solving iteratively harder tasks, but the knowledge from the old tasks helps us solve them. We can do this because the world around us is open-ended, and we can constantly try new experiments and create new artefacts in which us humans can learn new things from. Research in open-endedness tends to focus around how we could do this for reinforcement learning agents. Could we: 1) Create environments which are sufficiently complex to be constantly learnable (world models)? (see Genie for the most advanced version of this) 2) Create algorithms which can explore this vast search space in a meaningful way?
If you are interested in this, I would highly recommend reading some Jeff Clune’s or UCL Dark’s work on this.
Common Themes in Open-Endedness and Auto-Curriculums Research:
- Open-Endedness requires the generation of novel and learnable artefacts:
- Open-ended is defined in Open-Endedness is Key to ASI: a system is open-ended if it continually creates
novel and learnable artefacts. This is dependent on the observer, the memory and the time horizon.
Observer example: a mouse can’t learn chess and a computer will eventually plateau in performance. Open-endedness depends on the observer.
Time-horizon example: AlphaZero is open-ended in chess, but given enough time it will eventually plateau in performance.
Memory example: Wikipedia might appear open-ended to a human, who could constantly read it and learn new things they had forgotten the last time they read it. An LLM however might be able to memorise the entire thing, given enough weights.
- Open-ended is defined in Open-Endedness is Key to ASI: a system is open-ended if it continually creates
novel and learnable artefacts. This is dependent on the observer, the memory and the time horizon.
- Learnability metrics:
- Auto-curriculums need a way to be able to rank the novelness and learnability of levels. The main themes I have come across are:
- Learning errors: if the network can’t make good predictions about this state, it is likely learnable
- Performance: if the network always wins or always looses, there is nothing to be learned. This means AC prefer levels with a medium win-rate, e.g. 0.5.
- Auto-curriculums need a way to be able to rank the novelness and learnability of levels. The main themes I have come across are:
- Procedural Level Generation is used to create novel environments to learn in
- Procedural generation allows you to algorithmically create new levels, often parameterised by the curriculum.
E.g. MineCraft procedurally generates landscapes as you explore. This could be made into a curriculum by making resources near the user.
- Auto-curriculum methods can learn to choose parameters which are in teh zone of proximal development.
- E.g. POET introduces new level generation parameters, checks they meet a minimum learnability criterion and then only adds the most novel.
- Procedural generation allows you to algorithmically create new levels, often parameterised by the curriculum.
- Prioritized Level Replay is way to choose previous levels which are the most learnable
- Prioritized Level Replay suggest ranking levels by temporal‑difference error.
- Randomly generate a new level, or create a new one!: this creates population or pool of environments for the agent to interact with
- Auto-Curriculum Learning for Driving Scenarios, POET and many others methods introduces the idea of random generator + editor as the basic building blocks for creating levels. One creates random new levels and the other perturbs existing interesting levels. These new random levels are then tested and filtered to ensure they are sufficiently learnable.
- Curriculum generation can be more intelligent using Foundation Models
- FMs can act as ‘intelligent search operators’ to create new learning opportunities based on what they have learned that the agent would find difficult (e.g. EUREKAVERSE) or humans would find interesting (e.g. OMNI-EPIC).

Figure 2: OMNI-EPIC Architecture it uses to utilise Foundation Models to create interestingnovel scenarios through code [source](https://omni-epic.vercel.app/)
- This is suggested as a ‘key method on the road to ASI’. and is explored for level generation in OMNI-EPIC and EUREKAVERSE and for policy generation is Foundation Model Self-Play. LLMs are also used to iteratively improve prompts in GEPA.
- Performance annealed exploration reward:
- Curriculum Learning and Population-based Self-Play suggests using an exploration reward which is annealed according to agent performance. It therefore explores more when it is doing badly and exploits when it is doing well.
- Euclidean distance in the embedding space as a novelty metric:
- Many papers use Euclidean distance in the embedding space or feature space as a novelty metric: Foundation Model Self-Play, Enhanced POET, OMNI-EPIC. The basic premise is: the closer a new datapoint is to the others, the less novel it is.
- We can learn to learn to generate curriculums
- MM-ACL introduces a method to learn a model which predicts the improvement an agent will gain on a new level, from a history of its past performances. It is then used to generate new levels which have the highest possible performance improvement.
- DISCOVER uses value and uncertainty of an ensemble of critics to form an auto-curriculum for sparse-rewards
- Policy and values are conditioned on intermediate goal states (g) which are chosen to maximise novelty, achievability and relevance to goal state (g*).
- Insight:
- High V(s0, g) means tasks is likely achievable from start state s0.
- High std(s0, g) means this is not reliable and therefore likely novel
- High V(g, g*) means the sub-goal g is close to the target goal g* * We can therefore aim the agent an increasingly more difficult (but obtainable) goal.
- Parallelisable planning for model-based RL (GPU-able MCTS?!)
- SMX uses a particle filtering method to perform rollouts to identify a target to perform policy improvement.
- The advantage of using particle filters over MCTS is that they are entirely parallelisable (GPU-able!) and doesn’t require storing a tree.
- It also works for both continuous and discrete action spaces.
3. Pretraining, Fine-Tuning & General Training Tips
- Heterogeneous Pretraining: think outside the box when it comes to data
- Reasoning with Next Token Prediction (RNTP): (allowing the model to reason about the next token during pre-training)
- RL‑Pre‑Training suggests using next token prediction for RL but only applies in fine-tuning.
- Jack Morris’ blog post on scaling RL suggest that this might be way to squeeze the absolute maximum out of our ‘fossil fuel-like’ internet data.
- Next token prediction is verifiable so should allow us to get further performance on this internet data. We just need to work out how to scale LLM RL (see blog post and summary for further details).
- When doing PPO/GRPO, make the upper bound clip larger
- The upper clip bound being higher increases the probability of unlikely choices and increases exploration (as in ProRL and Play to Generalise) improve exploration and stability.
- Dual‑Outcome Reasoning: knowing what’s bad is also useful!
- Generating both best and worst moves in game scenarios deepens model understanding of decision boundaries (Play to Generalise).
- XLand did something analagous with their self reward-play, in which agents had to learn to achieve a goal but then also learn how to undo it, increasing their generalisability.
- Beware When Using Qwen for RL
- RL with Spurious Rewards shows that random reward signals can still improve performance on Qwen-2.5-maths. The authors explain that this is likely caused by RL encouraging the model to produce more code.
- Telling the model how to think improves performance (CoT prompting)
- FinCoT improved performance by giving the reasoning model **structured chain-of-thought prompts. For finance problems, methods to solve certain types of problems are well known, or at least the important things to look for. These chain of thought patterns are generated using DeepResearch and then added to the prompt after the question as a suggestion of how to think.
- Creating ‘soups’ of all your different hyperparameter fine-tuning models can improve performance.
- ModelSoups achieved SotA performance on ImageNet by doing a greedy mix (only add if it improves performance). This works as fine-tuned models often end up in the same loss valley and therefore averaging their performance can lead to lower loss and better performance.
- Prompt optimisation can outperform RL on single tasks
- GEPA showed that optimising prompts can be far more effective and sample efficient than GRPO. This done by mutating prompts according to feedback on the chain of thought from other LLMs (intelligent search operators! (1.7)). This makes sense if RL just increases the likelihood of using knowledge already baked into the model.
- General solvers through pre-training:
- GOAL trained a transformer to solve a set of combinatorial optimisation problems. Whilst it did perform slightly worse than tailor made solutions, it showed that features of these problems are shared and meant specialist solvers could be fine-tuned quickly. This was however trained on problems solved by dynamic programming. It would be interesting to see how this could be combined with DRL, perhaps using GPU environments to generate the vast amounts of data needed. 10 RL leads to less catastrophic forgetting than SFT:
- As explained in RL’s Razor, RL will choose a new policy closest to the original policy by gradually updating the non-zero probabilities. SFT does not do this, and rather drags the whole policy to a random point in the new task optimal policy space.
4. Robotics & Control
- Predict multiple actions at once rather than one
- Mimic One predicts chunks of actions to enforce temporal consistency.
- Using diffusion models as policies
- Learning world models from large scale video data
- V‑JEPA pretrains on millions of videos to predict missing frames, then fine‑tunes on robotic datasets for causal understanding and planning.
- Pre-Training is possible in robotics
5. Distribution
- This blog post by Jeremy Jordan covers the basics of how to train a network on thousands of GPUS. Some of the key methods spoke about were:
- Types of parallelism:
- Data parallelism: each GPU has a copy of the model and a different batch of data. They then share gradients to do joint updates.
- Model parallelism: for large models. Model layers are split over many GPUs.
- Communication methods:
- Scatter: send different data to each GPU
- Broadcast: same data to all
- Reduce: combine all data on one GPU.
- Types of parallelism:
- This blog post on distributed PPO outlines some extra factors to think about:
- Synchronous: waits for all agents to calculate their respective gradients before doing a weights update.
- Asynchronous: doesn’t wait.
- Centralised: single server does all gradient accumulation and weights updates.
- Decentralised: all share gradients (all-reduce) but have their own model.
- IMPALA outlines a now common, distributed reinforcement learning method with multiple actors and a single centralised learner
which broadcasts weights update. This is mimicked in PyTorch in TorchBeast.
- V-trace is an important part of this setup. It utilises importance sampling to account for the data being collected being more and more off-policy every moment.
- Decentralised PPO can scale better
- DD-PPO scales PPO almost linearly up to 128 parallel agents using decentralised, synchronous training.
- It crucially relies on a preemptive threshold to end rollouts and start training once a high number of environments are finished and only stragglers remain.
- Docker can be used like a lightweight virtual machine for distributing actors or learners across large clusters.
6. Multi‑Agent Reinforcement Learning (MARL)
- Stabilise MARL by condition agents actions on the actions of other agents
- JointPPO orders agents by decision importance, then uses a recurrent action‑conditioned network to generate actions sequentially
- GPU based environments are key to tackling to complexity of MARL
- JaxMARL allows you to run the environment tens of thousands of times in parallel. This means the monumental search space can be explore a bit more thoroughly.
- Population‑based methods prevent overfitting and foster diverse behaviors and can help tackle non-transivity
- Technique is used in TiZero, OpenAI Five, AlphaStar and more
- Focus on playing the agents which you struggle against. (similar to curriculums)
- Agent selection via ELO‑weighted sampling encourages robustness and competitive balance. This is used in Multi-Agent Pommerman, AlphaStar and more.
- More simple heuristics can be used (e.g. TiZero used $(1-p)^2$ (p: probability of victory against opponent) to define a probability distribution which encourages you to focus on agents you cant beat
- TiZero Football: Strong implementation example of many-on-many competitive and collaborative game
- Their paper provides a strong example of a system designed to play many-on-many games and gives a detailed account of the architecture choices, curriculum and self-play methodology.
7. Self‑Improvement Strategies
- LLMs can do self-play for reasoning, as long as their grounded to reality
- Absolute Zero Reasoner creates coding puzzles in a self-play method, SPIRAL introduced a paradigm of self-play through text-based games.
- Unsupervised Self‑Dialog Games
- VLMs play in‑domain “Guess Who” style games to self‑improve vision‑language reasoning. (VLM Self‑Dialog Games)
- Adaptive Prompting & Team Agents
- Agents of Change evolve prompts and orchestrate agent teams (analyst, coder, researcher) for strategic planning tasks.
- Self‑Adapting LLMs
- SEAL uses RL to generate synthetic edits and hyperparameters, enabling rapid adaptation to new tasks.
8. Architectures:
- Rohit Bandaru’s blog post summaried Yann Lecuns JEPA architecture and made the following suggestions:
- A framework for human-level AI: includes a bunch of different parts which all play a role found in the human brain.
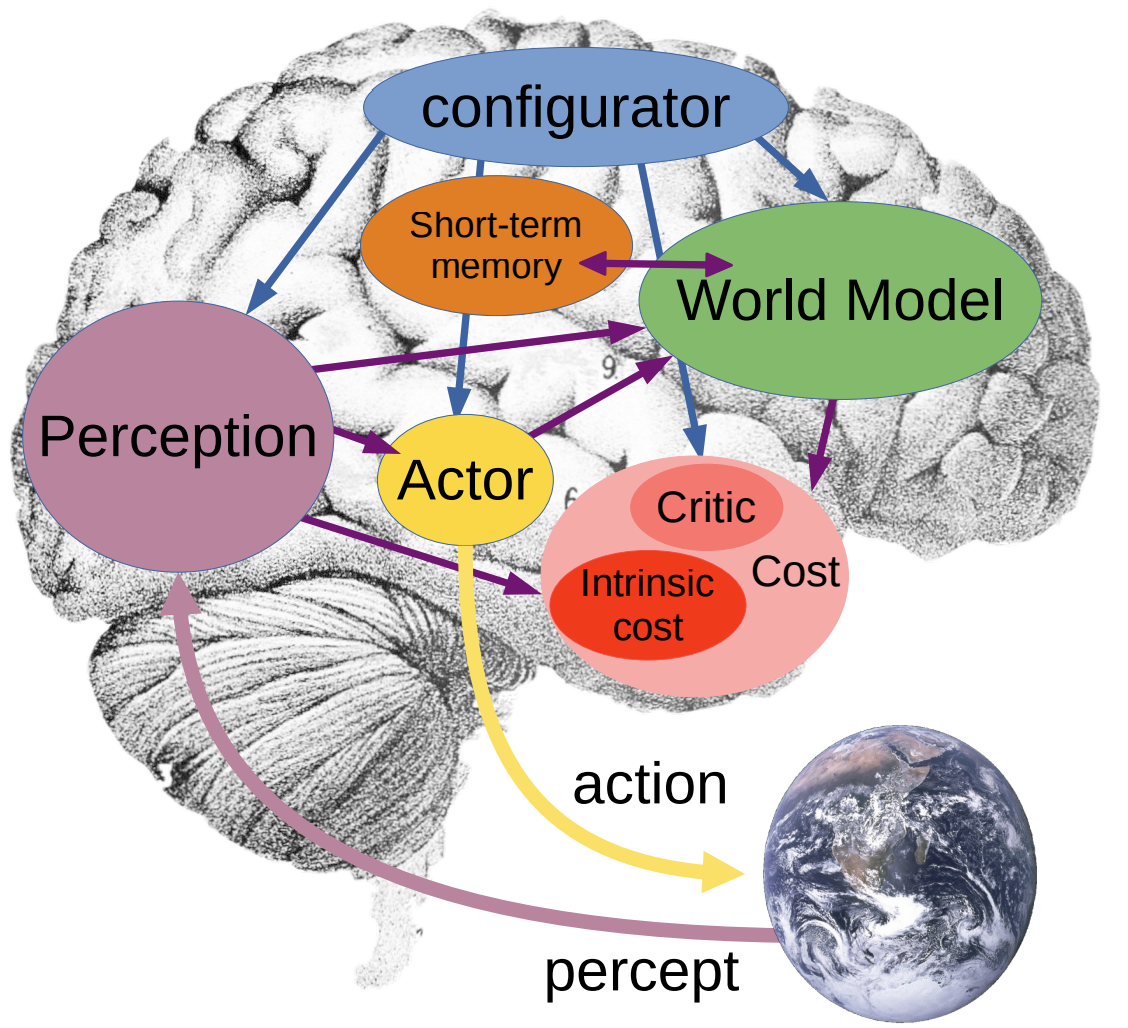
Figure 1: Yann Lecun's architecture for human level AI [source](https://openreview.net/pdf?id=BZ5a1r-kVsf)
- Energy Based Models:
- Energy based models predict how plausible a future state is.
- It’s impossible to know what will happen in the next state… but it possible to predict a latent representation of it.
- EBM aim to predict the distance between the embedding of current and future state.
- There is however still uncertainty, so a random variable is used in the prediction of future state to account for this randomness.
- A framework for human-level AI: includes a bunch of different parts which all play a role found in the human brain.
- Hierarchical multi-timescale planning:
- When humans plan we do it at multiple timescales. When you think “I’m going to go to work”, you don’t think about every single joint movement you are going to do to get there. You plan the highest level actions and then break them down into sub-tasks. This is what Yann Lecun suggests and is what Hierarchical Reasoning Model implements. A high level planner runs at a low frequency while a high frequency recurrent neural network performs the plans which the high level planner creates.
- Interesting Observation Spaces:
- CTMS for the German Deutsche Bahn used tree structure to model the railway in front of each train
- Graphs are a great way to represent data which includes relationships
- Intro to Graph Neural Networks provides a great intro to graphs and how we can build neural networks to learn things about them. It also introduces key ideas like how to present the network the edges, how to batch varying sized graphs and message passing.
- Graph Transformers provide a highly capable model for evaluating graphs. Their self-attention models connections between all nodes and/or edges. As is the case with transformers, this does come at high compute and memory cost. A GT was applied in RL context in this paper.
9. Quantisation
- Maarten Grootendorst’s blog post on quantisation for LLMs give a nice intro to the topic with some intuitive explainations. A brief overview:
- Quantisation:
- Reducing the precision of a model’s numerical representation tp reduce its memory overhead.
- This essentially means storing high precision datatypes such as float32 as smaller datatypes such as uint8
- Why quantise?
- LLMs required billions of parameters and therefore massive amounts of memory… smaller datatypes = less memory footprint
- Using smaller datatypes runs faster (faster memory access, more parallelism, integer accelerated operations)
- Techniques:
- Linear mapping:
- Symmetric: scales all values by s and then used a signed integer (range is -max to +max)
- Asymmetric: scales and then applies bias such that range is min to max (more efficient and precise)
- Clipping and calibration:
- Including outliers can massively reduce precision, as they increase range.
- Methods often set a reasonable range (e.g. +-5std) and then clip the rest of the values
- Activation quantisation: you don’t know the activation range during training and therefore must come up with a strategy
to quantise them when they appear:
- Dynamically quantised: calculate scale and zero-point during inference
- Staticly quantised: a quantisation rate is set before inference on a pre-defined dataset.
- Linear mapping:
- Types:
- Post Training Quantisation:
- Weights are quantised after training
- Quantisation Aware Training
- Quantises and dequantises during training such that the model can locate the best minima which accounts for its effects.
- Often lowers FP32 accuracy (no quant) but increases accuracy in low precision models (e.g. int4)
- Post Training Quantisation:
- Quantisation:
10. GPU Architecture and PyTorch
- Architecture:
- GPUs have two layers of parallelisation.
- WARP level: warps are groups of 32 threads which are executed at the same time. They have the same operation performed on them. If they require different operation, multiple operations are performed and masked in a process known as warp divergence.
- Streaming Multi-Processors (SM): there are many SMs on a GPU (second level of parallelisation). These each have shared L1 memory and their own warp schedulers.
-
Sources: Nvidia GPU fundamentals, []
- Memory:
- L2-cache: small but very fast access memory
- High Bandwidth Memory or DRAM (RAM of the GPU):
- Stores data and instructions before they are loaded into L2-cache for execution
- Warp schedulers: hide latency (instruction dependence, memory reading etc.) by overlapping warps. This is what allows linear time increases beyond the number of cores.
- CUDA cores:
- General purpose core inside each GPU which can do many operations (e.g. add, element wise add etc.)
- Perform one FMA per cycle
- Tensor cores:
- Specialised units inside each SMs for Fused Multiply Accumulate (FMA)
- Perform FMA of entire tile per cycle rather than one FMA per cycle.
- Performance heavily relies on the matrix breaking down nicely for tiles for the TC, otherwise performance drops.
- GPUs have two layers of parallelisation.
- Performance:
- Compute light operations (activations, norms etc) will often be memory limited meaning the speed at which the data can be loaded is the bottleneck.
- There’s not loads you can do about this, other than to try and limit the number of read and writes and check for an optimised implementation.
- Check arithmetic intensity to predict whether an operation is memory limited
- Quantisation:
- Tile quantisation: wasted compute as a result of matrices not dividing perfectly into tiles.
- GPUs perform matrix multiplications in tiles. Whether there is just one column filled, or the entire tile, the GPU performs the same amount of computation.
- Therefore if the matrix is not made up of an integer number of tiles, there will be a tail at the end in which a whole tile is computed for an incomplete tile.
- E.g. if the tile size is 128, increase the rows from 256 to 257 will increase compute by 50%
- Wave quantisation: wasted compute as a result of the number of tiles not dividing perfectly into the number of streaming multi-processors.
- Similar process to above, but with SMs.
- If the number of tiles does not divide nicely into the number of SMs, there will be a tail in which compute is not fully utilised.
- Tile quantisation: wasted compute as a result of matrices not dividing perfectly into tiles.
- Tensor cores:
- Check your GPUs datasheet and make sure the dimensions of your batch divide nicely for the tensor cores. This normally means making sure they all divide by 8.
- Having tails will result in under utilisation of tensor cores or them not being used at all in some older GPUs.
- Custom kernels in Triton can often help if we have specialist use case in which the default kernels don’t perform well.
- Compute light operations (activations, norms etc) will often be memory limited meaning the speed at which the data can be loaded is the bottleneck.
- PyTorch details (and some details on the internals))
- Eager execution results in overhead when the CPU launches kernels on the GPU. Use torch compile or cuda graphs to fuse kernels and lower the overhead of executing these commands (this is however less significant at higher batch sizes).
- Maintain static input sizes to stop torch having to re-allocate memory
🛠️ Method
Identification of Papers
- X (Twitter): there is a huge AI community on twitter which post papers with discussion in the comments.
- TIP: If others choose to use this I would highly recommend using the ‘Not Interested’ feature on posts, otherwise your feed will rapidly deteriorate and show less papers.
- Reddit: r/MachineLearning
- Conferences: I recently attend ICLR and came back with a treasure trove of interesting reads.
- Paper references
Use of LLMs
- LLMs are NOT used for the analysis of the papers. They are however used for checking. I read the paper, write down what I think the key points are. I then ask o4-mini-high to do the same and double check if we disagree.
- Paper recommendations
- Formatting and helping with markdown.
- Quick analysis scripts.
⚙️ Repository Structure
├── LLM_reinforcement_learning/ # Papers on RL with language models
├── marl/ # Multi‑agent RL resources
├── non_LLM_reinforcement_learning/ # RL methods outside LLM context
├── robotics/ # Robotic learning and control papers
├── self_improvement/ # Self‑play and self‑dialog approaches
├── distribution_and_gpu_acceleration/ # GPU‑accelerated training methods
├── open_endedness_and_auto_curriculums/ # Curriculum learning and open‑endedness
└── README.md # This overview and highlights
📖 Full Diary
Click the links to see the summaries and get links to the original paper.
May 2025
- 23rd: Absolute Zero Reasoner:creates self-play learning paradigm in which the LLM learns to both propose and answer reasoning problems grounded by a coding engine.
- 24th: π_{0.5}: a Vision-Language-Action Model with Open-World Generalization: VLA pre-trained on heterogeneous data which deploys hierarchical planning to complete natural language tasks.
- 25th: TD-MPC2: Scalable, Robust World Models for Continuous Control: algorithm to learn a latent space world model for mod predictive control.
- 26th: JointPPO: Diving Deeper into the Effectiveness of PPO in Multi-Age Reinforcement Learning : a transformer outputs a sequence of actions, conditioned on the output of previous actions for MARL. The order is decided by an importance network.
- 29th: Synthetic Experience Replay: a diffusion model is trained to create new data examples in a replay buffer.
- 30th: Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment: addresses credit assignment problem by adding a weighted turn and trajectory based reward.
June 2025
- 1st: Ultimate Guide to Supervised Fine-Tuning: a long guide covering all the different methods for fine-tuning LLMs.
- 2nd: Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations (Demo Augmented RL): method to mix generated experiences in with expert examples during RL.
- 3rd: Spurious Rewards: Rethinking Training Signals in RLVR: shows that giving Qwen random rewards can improve its score on RL benchmarks.
- 4th: ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models: a method for for RL to have continuing improvement for a large number of episodes.
- 5th: JaxMARL: Multi-Agent RL Environments and Algorithms in JAX: a set of Jax GPU environments for training multi-agent RL.
- 8th: Illusion of Thinking: Understanding Strengths and Limitations of Large Reasoning Models (LRMs): creates doubt on whether reasoning models are really doing any ‘thinking’
- 9th: CHIRPs: Change-Induced Regret Proxy Metrics for Lifelong Reinforcement Learning: similarity metric for two MDPs.
- 9th: Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and their Solutions: POET creates an open-ended framework for training diverse and ever improving RL agents.
- 10th: Reinforcement Pre-Training: allows model to perform CoT RL on each token during post-training.
- 11th: Reinforcement Learning Teachers of Test Time Scaling: trains an LLM to explain problems such that another LLM can learn from that explanation
- 11th: Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning: only trains on high entropy tokens during RL reasoning.
- 12th: Writing-Zero: Bridge the Gap Between Non-verifiable Tasks and Verifiable Rewards: trains a preference model for the non-verifiable reward task of creative writing.
- 16th: Play to Generalize: Learning to Reason Through Game Play: trains reason on games, i.e. what is the best and worst move, to improve performance on benchmarks such as maths
- 17th: mimic-one: a Scalable Model Recipe for General Purpose Robot Dexterity
- 18th: Prioritised Level Replay: replays levels with the highest temporal difference error, assuming those are the most learnable.
- 19th: Self-Adapting Language Models: aims to encourage continual learning and increase learning efficiency by editing its own training data.
- 20th: Agents of Change: Self-Evolving LLM Agents for Strategic Planning:
- 21st: KINETIX: INVESTIGATING THE TRAINING OF GENERAL AGENTS THROUGH OPEN-ENDED PHYSICS-BASED CONTROL TASKS: trains a generalisable 2D kinematics solver using vast quantities of training data generated on the GPU.
- 22nd: Superintelligence From First Principles (blog post): discusses possible pathways for reaching an AI which can outperform humans at all tasks.
- 23rd: Automatic Curriculum Learning for Driving Scenarios: Towards Robust and Efficient Reinforcement Learning: creates an auto-curriculum for driving scenarios to prevent overfitting but without sample inefficiency of domain randomisation.
- 24th: How Visual Representations Map to Language Feature Space in Multimodal LLMs: investigates where visual and text representations unify in a VLM.
- 25th: Multi-Agent Training for Pommerman: Curriculum Learning and Population-based Self-Play Approach: auto-curriculum for Pommerman using performance annealed exploration rewards.
- 26th: Automatic Curriculum Design for Zero-Shot Human AI Coordination: creates a curriculum for human and AIs to compliment one another. This is achieved by encouraging a diverse enough population such that a human like agent hopefully be represented.
- 28th: OMNI-EPIC: Open-Endedness Via Models of Human Notions of Interestingness With Environments Programmed In Code: utilises foundation models to generate code for RL environments which a human would find interesting.
- 30th: Self-Supervised Video Models Enable Understanding, Prediction and Planning (V-JEPA): creates a latent space world model using video data
July 2025
- 1st: Open-Endedness is Essential for Artificial Superhuman Intelligence
- 2nd: SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning
- 4th: Training extremely large neural networks across thousands of GPUs by Jeremy Jordan
- 5th: IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
- 5th: TorchBeast: A PyTorch Platform for Distributed RL
- 7th: Distributed PPO Blog Post
- 8th: Reinforcement Learning with Docker
- 9th: FinCoT: Grounding Chain-of-Thought in Expert Financial Reasoning
- 10th: Illuminating search spaces by mapping elites
- 11th: Foundation Model Self-Play: Open-Ended Strategy Innovation via Foundation Models
- 12th: How to scale RL to 10^26 FLOPs blog by Jack Morris
- 13th: INTELLECT-1 Technical Report
- 14th: Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
- 15th: Synergizing Quality-Diversity with Descriptor-Conditioned Reinforcement Learning
- 16th: What Has a Foundation Model Found? Using Inductive Bias to Probe for World Models
- 17th: Deep Dive into Yann LeCun’s JEPA by Rohit Bandaru
- 18th: All AI Models Might Be The Same by Jack Morris
- 19th: Multi-Agent Diagnostics for Robustness via Illuminated (MADRID)
- 20th: Assessing the Zero-Shot Capabilities of LLMs for Action Evaluation in RL
- 20th: TiZero: Mastering Multi-Agent Football with Curriculum Learning and Self-Play
- 22nd: Model-Based Meta Automatic Curriculum Learning
- 23rd: Eurekaverse: Environment Curriculum Generation via Large Language Models
- 25th: Benchmarking Population-Based Reinforcement Learning across Robotic Tasks with GPU-Accelerated Simulation
- 26th: DISCOVER: Automated Curricula for Sparse-Reward Reinforcement Learning
- 27th: Winner Takes It All: Training Performant RL Populations for Combinatorial Optimization
- 28th: Dispelling the Mirage of Progress in Offline MARL through Standardised Baselines and Evaluation
- 29th: Communicative Reinforcement Learning Agents for Landmark Detection in Brain Images
- 30th: Intelligent Railway Capacity and Traffic Management Using Multi-Agent Deep Reinforcement Learning
- 31st: Gym4ReaL: A Suite for Benchmarking Real-World Reinforcement Learning
August 2025
- 1st: GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
- 2nd: Forecaster: Towards Temporally Abstract Tree-Search Planning from Pixels
- 4th: Hierarchical Reasoning Model
- 5th: GOAL: A Generalist Combinatorial Optimization Agent Learner
- 6th: A Survey of Graph Transformers: Architectures, Theories and Applications
- 7th: A Gentle Introduction to Graph Neural Networks
- 8th: Graph Based Deep Reinforcement Learning Aided by Transformers for Multi-Agent Cooperation
- 9th: Open‑Ended Learning Leads to Generally Capable Agents
- 10th: Sable: a Performant, Efficient and Scalable Sequence Model for MARL
- 11th: SMX: Sequential Monte Carlo Planning for Expert Iteration
- 13th: ProRL V2 - Prolonged Training Validates RL Scaling Laws
- 16th: Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
- 18th: The 37 Implementation Details of Proximal Policy Optimization
- 21st: Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
- 22nd: Hybrid Actor-Critic Reinforcement Learning in Parameterized Action Space
- 23rd: DD-PPO: LEARNING NEAR-PERFECT POINTGOAL NAVIGATORS FROM 2.5 BILLION FRAMES
- 26th: The Bitter Lesson
September 2025
- 1st: In-Context Reinforcement Learning for Variable Action Spaces
- 3rd: Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX
- 5th: Efficiently Quantifying Individual Agent Importance in Cooperative MARL
- 7th : Maarten Grootendorst’s blog post on A Visual Guide to Quantization
- 13th : Following Jax MNIST tutorials
- 14th: Compiling machine learning programs via high-level tracing
- 14th - 15th: How to think about GPUs by Google DeepMind
- 16th: RL’S RAZOR: WHY ONLINE REINFORCEMENT LEARNING FORGETS LESS
- 21st: PyTorch Internals by Edward Wang
- 22nd: What is Torch Compile?
- 23rd JIT Compilation in JAX
- 23rd: CUDA Study Log 4: Optimizing Constrained Decoding with Triton Kernel
- 24th: Accelerating PyTorch with CUDA Graphs
- 26th: PyTorch Performance Tuning Guide
- 27th: Nvidia Docs: GPU Performance Fundamentals
- 27th: Nvidia Docs: Optimising Memory Limited Layers
- 28th: Nvidia Docs: Matrix Multiplication and Quantisation Background
- 30th: On the Design of KL-Regularised Policy Gradient Algorithms for LLM Reasoning
October
1st: Current Best Practices for Training LLMs from Scratch
More Plots
Papers Read Over Time
U-MAP
The t-SNE for comparison: